关于现代Web系统架构的分析报告
1. 引言
本报告旨在探讨不同规模公司在系统架构、云原生实践以及开发架构上的差异与演进路径。通过梳理、数据提取和可视化呈现,将核心观点以更具结构化和可读性的方式呈现,以期为技术决策者和架构师提供有价值的参考。
2. 核心洞察
本文的核心观点可以概括为:架构的演进与选择并非纯粹的技术问题,而是由业务规模、成本、人才密度和战略共同决定的复杂权衡。
-
一线公司(如阿里、字节)的架构核心驱动力是突破物理极限和极致降本,因此倾向于深度自研,构建技术护城河,其架构呈现出平台化、多地多活、强一致的特征。
-
二三线及中小公司的核心驱动力是快速交付业务和保证系统稳定,因此更倾向于拥抱开源方案和公有云托管服务,通过“拿来主义”实现降本增效,其架构演进更注重敏捷性和成本效益。
-
云原生是当前架构演进的大趋势,但落地实践需因地制宜。对中小公司而言,直接拥抱Serverless和托管服务(如AWS Fargate)可能比自建Kubernetes集群更为明智。
架构考虑因素:
- 市场阶段(开发架构选择)
- 实现MVP,进行产品可行性验证。
- 市场调研完毕,进入正式开发迭代阶段。
- 预期规模
- 百级并发。
- 千万数据,峰值几千-一万并发。
- 亿级数据,峰值一万-十万并发。
- 数十亿数据,峰值几十万并发。这是国内一线大厂的核心业务的规模。
- 业务复杂性
- 业务简单,比如管理系统,工作流。
- 业务一般复杂,比如招聘网站,中型电子商务平台。
- 业务非常复杂,比如金融系统,大型电子商务网站,通常在核心业务中涉及极为复杂的业务逻辑。
- 目标客户位置
- 国内
- 国外
- 现状
- 技术现状
- 审计要求
- 成本账单: 架构不只是技术,还是钱。不同规模下,硬件和人力成本的平衡。
《AI 背景下的架构实战系列(干货版)》,计划出7个视频,讲解对于不同规模、不同现状的公司的架构选择。
第一集:回归本质:AI 原生时代的架构演进与“反向重构” 核心干货: 为什么有了 AI Copilot 后,复杂的微服务反而成了负担?讲解“单体回归(Monolith First)”在 AI 开发背景下的效率优势,以及如何设计易于 AI 维护的模块化架构。
指导意义: 帮助架构师判断什么时候该拆服务,什么时候该合并。
第二集:出海架构实战:如何利用 Serverless 与边缘计算构建全球化 MVP 核心干货: 对比 AWS Lambda/Vercel 与传统的 K8s 部署成本;如何利用 AI 自动化处理不同国家的合规检测(如 GDPR/CCPA);解决跨海网络延迟的“边缘网关”方案。
指导意义: 给没钱、没人的团队一套“免运维”且全球可用的架构模版。
第三集:国内极速响应:在流量内卷与高频迭代中构建弹性架构 核心干货: 针对国内小程序、直播等生态,讲解“读写分离+多级缓存”的极致优化;如何在 AI 驱动的低代码平台上预留扩展接口。
指导意义: 指导开发者如何在 2 周内上线并扛住首波推广流量。
第四集:千万级基石:高性能 SQL 与缓存策略,绕过分库分表的“大坑” 核心干货: 2026 年的现代数据库性能分析;讲解如何通过合理的索引设计、Redis 多级缓存规划以及向量数据库的集成,承载万级 QPS。
指导意义: 提供一套清晰的数据量级/并发量对应的技术选型表。
第五集:复杂业务拆解:基于 DDD 与 AI Agent 工作流的系统建模 核心干货: 当业务逻辑超出人脑理解范围时,如何应用领域驱动设计(DDD);如何将死板的硬编码逻辑,重构为“智能体协作(Agentic Workflow)”模式。
指导意义: 解决中大型项目中业务耦合、代码难以维护的顽疾。
第六集:跨越亿级门槛:高可用架构的“自愈”设计与瞬时洪峰对抗 核心干货: 深度剖析限流、熔断、降级在 AI 预测下的自动化实现;亿级数据下的冷热分离方案与分布式事务的最终解决方案。
指导意义: 给出系统在极端压力下“保命”的 checklist。
第七集:大厂架构平替:从阿里/腾讯的工程实践中提取“架构公约数” 核心干货: 剥离大厂昂贵的自研组件,寻找社区最强的开源替代品(如 TiDB, SkyWalking, SeaTunnel);讨论如何将大厂的 GPU 调度与算力优化经验应用到普通企业。
指导意义: 让中小企业也能拥有“大厂级”的稳定性。
🛠️ 为了让课程更具“指导作用”,建议你每集包含以下三个模块: 架构对比表: 方案 A(省钱型)vs 方案 B(高性能型)vs 方案 C(AI 自动化型),列出各自的成本、上线时间和维护难度。
避坑指南: 亲身经历或真实调研过的“这里有个坑,千万别这么搞”。
2026 选型建议: 明确给出具体的开源组件或云产品组合方案。
3. 不同规模公司的架构差异分析
公司所处的发展阶段和业务体量,直接决定了其技术架构的形态和复杂度。一线公司与二三线公司在技术选型、资源投入和人才战略上存在显著差异。
3.1 架构能力与资源规模对比
一线公司在技术深度、自动化、容灾能力等方面均大幅领先,这背后是巨大的资源投入。通过下面的雷达图和柱状图,可以直观地看到两者在架构能力和资源规模上的差距。
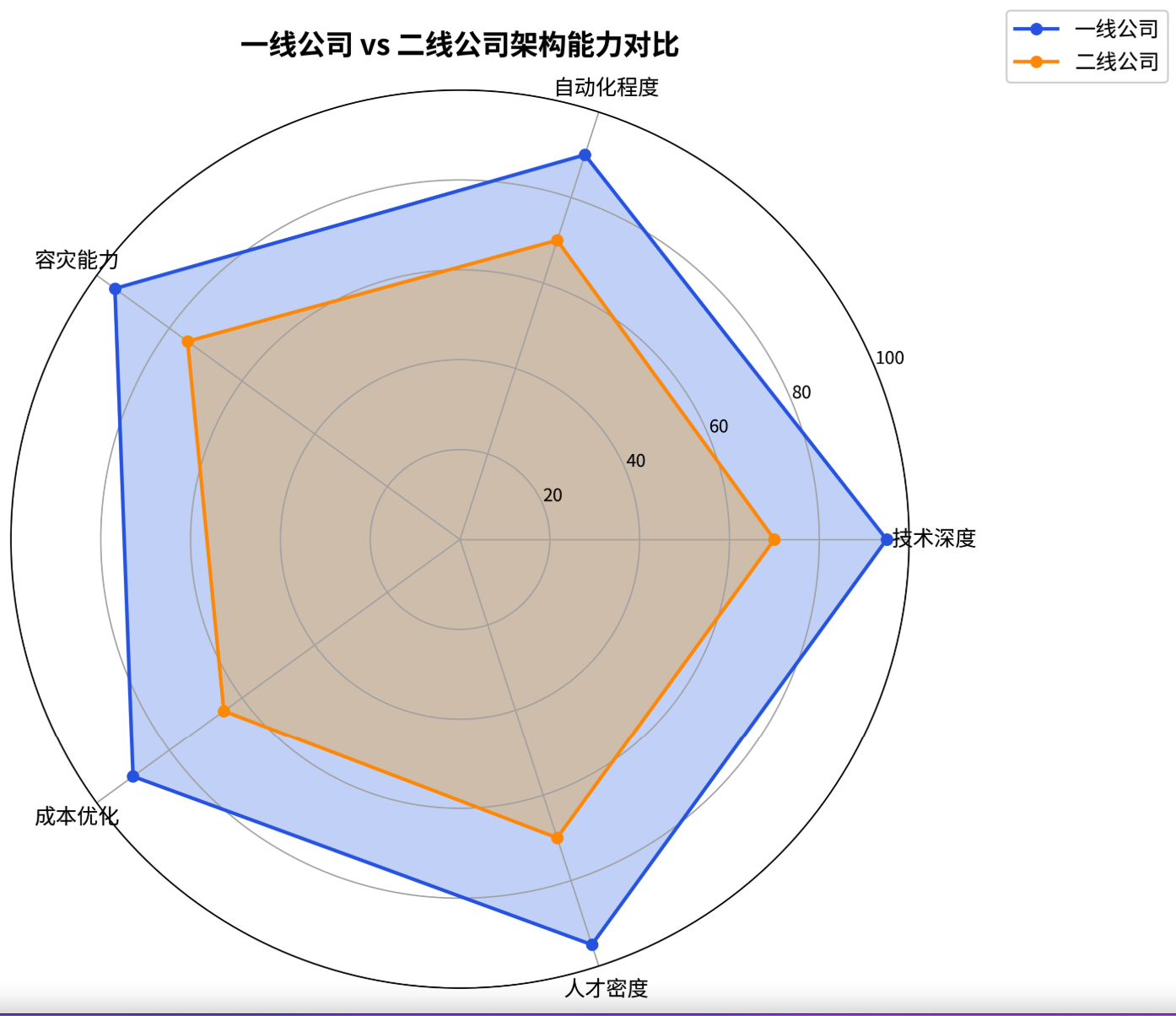
图1:架构能力雷达图 - 该图清晰地展示了一线公司在技术深度、自动化、容灾、成本优化和人才密度五个维度上的综合优势,其能力边界远超二线公司。
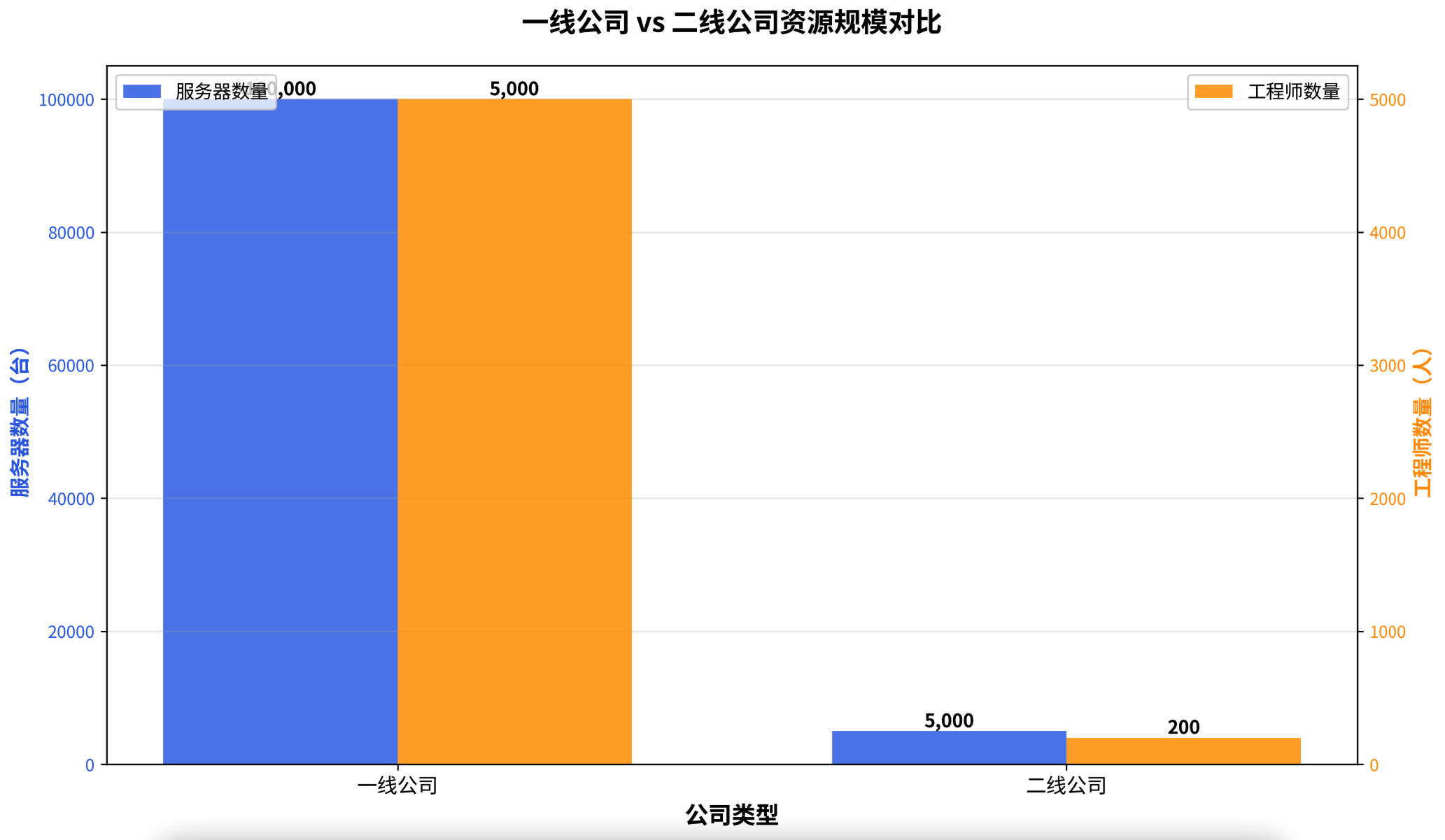
图2:资源规模对比柱状图 - 该图揭示了支撑强大架构能力背后的人力和服务器资源投入。一线公司动辄数十万台服务器和数千名工程师的体量,是二三线公司难以企及的,这也解释了为何两者在架构策略上会分道扬镳。
3.2 技术选型策略:自研与开源
技术选型是架构差异的直接体现。一线公司倾向于“造轮子”,通过自研解决极限场景下的性能瓶颈;而二线公司则更倾向于“用好轮子”,最大化利用成熟的开源和云服务。
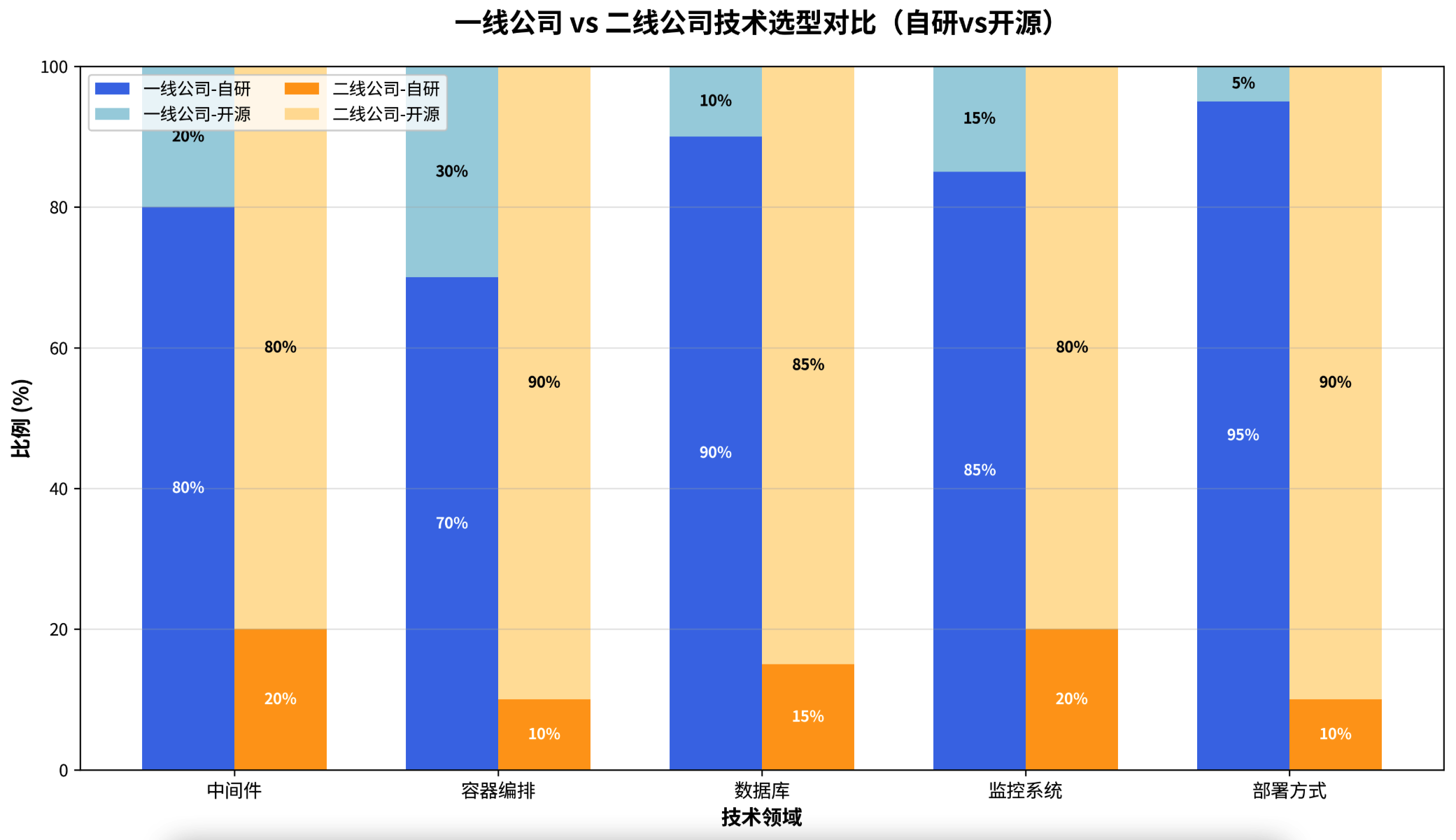
图3:技术选型对比图 - 该图显示,一线公司在数据库、中间件等核心领域的自研比例远高于二线公司,而二线公司则几乎完全依赖开源方案。这反映了两者在技术投入和风险偏好上的不同策略。
3.3 架构演进路径
两种规模的公司,其架构演进路径也截然不同。一线公司走的是一条从“集成”到“重构”再到“定义标准”的道路,而二线公司则是在“集成”的基础上,向“托管”和“业务优化”方向发展。
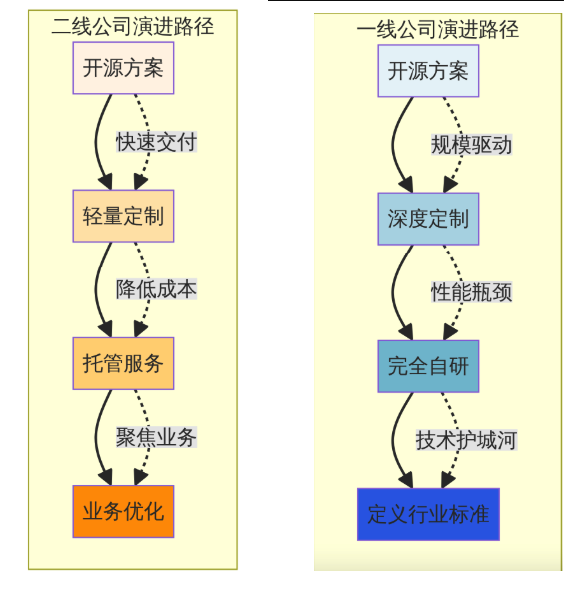
图4:架构演进路径图 - 该图描绘了不同驱动力(如规模、性能、成本、交付速度)如何引导公司走向不同的技术演进方向。
4. 云原生架构深度解析
云原生是一套面向云环境设计的架构理念和技术体系,其核心在于充分利用云的弹性、分布式和自动化能力。它并非单一技术,而是一个由微服务、容器、服务网格、DevOps等组成的综合生态系统。
4.1 云原生系统架构
一个典型的云原生系统架构如下图所示,它通过分层解耦,实现了敏捷开发、弹性伸缩和故障自愈。
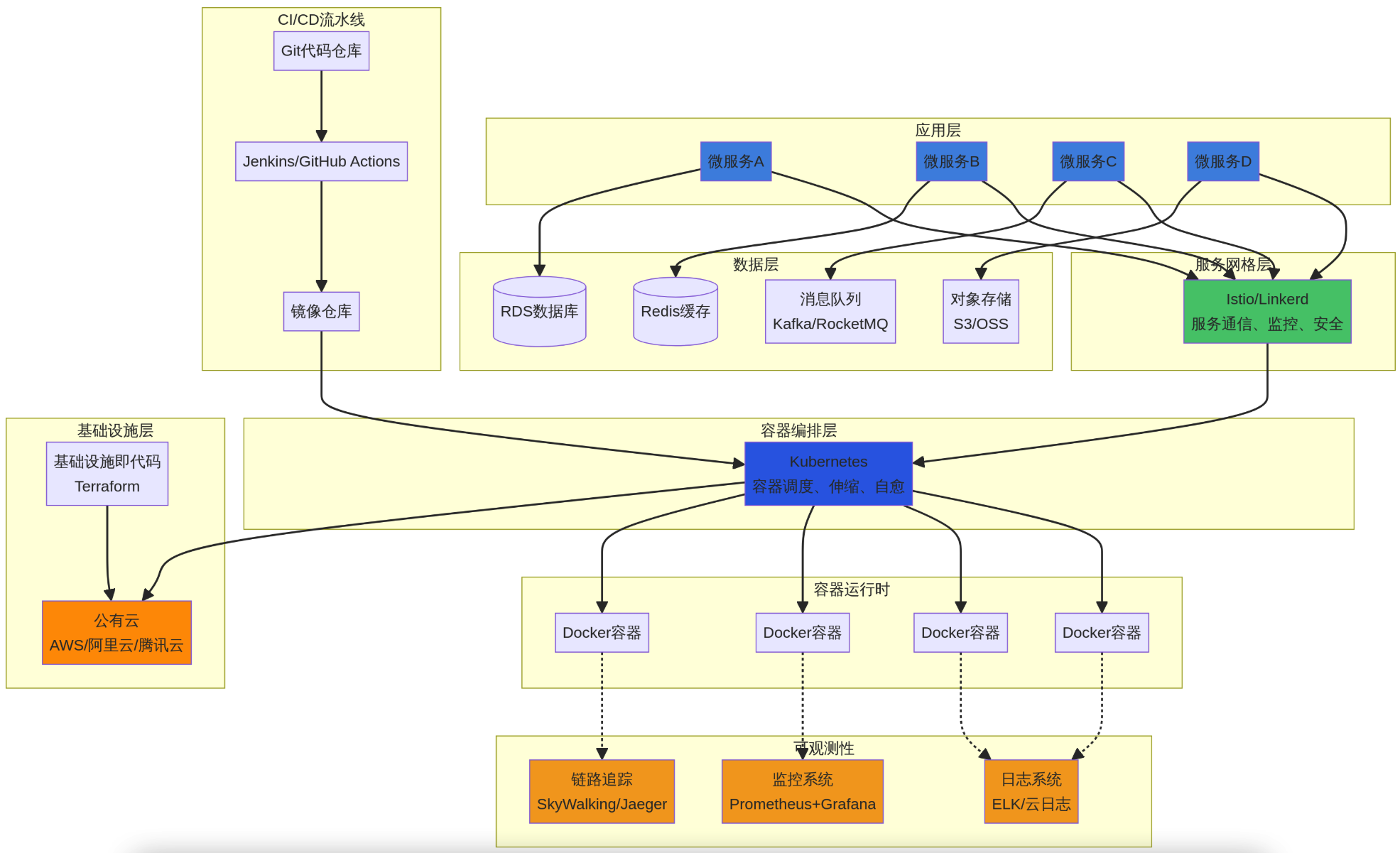
图5:云原生系统架构图 - 该架构图展示了一个典型的分层云原生应用。从底层的公有云基础设施,到容器编排、服务网格,再到上层的微服务应用,各层组件协同工作,共同构成了现代化的、高可用的系统。
4.2 云原生落地演进路径
对于希望向云原生转型的二三线公司,给出一个清晰的四阶段演进路线图,旨在帮助其平滑、低成本地完成转型。

图6:云原生演进时间线 - 该图建议的演进路径强调循序渐进,从最容易实现且收益最高的容器化入手,逐步过渡到微服务、可观测性,最终实现自动化和成本优化,避免了一步到位的“大跃进”式转型带来的风险。
5. 开发架构与工程实践
除了基础设施架构,开发架构和工程实践的差异同样显著。一线公司拥有极其完善和标准化的开发流程(Engineering Rigor),强调代码评审、文档先行和自动化测试,分工精细。而二线公司则更注重交付速度和灵活性,工程师往往需要具备“全栈”能力,以应对快速变化的业务需求。
| 维度 | 一线公司 | 二线公司 |
|---|---|---|
| 代码评审 | 极其严格,关注规范、设计、扩展性 | 相对宽松,关注逻辑正确性 |
| 发布流程 | 完善的灰度、回滚、监控联动机制 | 流程简单,测试与生产环境为主 |
| 文档要求 | 强调“文档先行”,设计评审驱动开发 | 文档可能滞后,口头沟通较多 |
| 人才模型 | 专家型 (Specialists),领域深耕 | 通才型 (Generalists),能力全面 |
6. 总结与建议
通过本文的分析,我们可以得出以下结论:
-
没有最好的架构,只有最合适的架构。 公司在选择架构时,必须充分考虑自身的业务阶段、资金和人才状况,切忌盲目追随大厂的技术潮流。
-
云原生是方向,但路径需务实。 对于绝大多数中小公司而言,善用公有云的托管服务是实现云原生价值的最佳捷径。与其投入巨大成本自建和维护复杂的K8s集群,不如将精力聚焦于业务逻辑本身。
-
架构师的角色正在演变。 在二三线公司,架构师需要具备更广阔的技术视野和业务感知能力,成为连接技术与业务的桥梁,而不仅仅是某个领域的技术专家。
本报告建议,技术团队在进行架构规划时,可以参照文中的对比和演进路径,明确自身定位,制定出符合实际情况的技术战略。